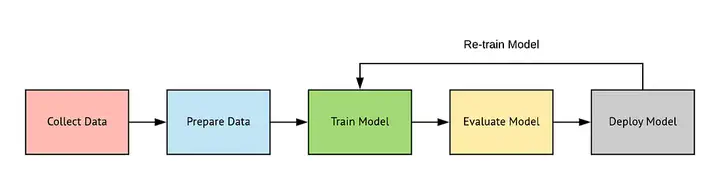
This project demonstrates my ability to implement a highly scalable MLOPS project by following development techniques and project procedures. In this project, I divided the whole implementation part into six different pipelines and steps, which are as follows:
Data Ingestion: Collecting the data and setting it up for further use.
Data Validation: Checking the data type, format, and other conditions to see the validity and usability of the data.
Data Transformation: Performing preprocessing and splitting the data into test and train datasets.
Model Training: Selecting a suitable machine learning algorithm and creating a model by training.
Model Evaluation: Testing the data and verifying it with measurement/result metrics.
Model Prediction: Making predictions with user input.
Each pipeline step followed a particular workflow in order to complete the pipeline successfully. See the following:
- Update config.yaml
- Update schema.yaml
- Update params.yaml
- Update the entity
- Update the configuration manager in the src config
- Update the components
- Update the pipeline
- Update the main.py
- Update the app.py
Follow the above workflow based on your current pipeline.
Follow this markdown link to generate the base structure of your root repository for your project in order to implement MLOPS.
Uses a mail flow for model registry and the model monitoring and model can be deployed from ML flow only
Here is the tracking URL of my Molde link
Ukant Jadia
Graduate | ML & Software Engineer
My research interests include applied machine learning, visualization, programming boring stuff.