Federated Learning vs. De-Anonymization -- Protecting Your Data
De-Anonymization is the only Solution?
Federated Learning vs. De-Anonymization: Protecting Your Data
In simple terms, federated learning is a technique where a machine learning model is shared with different nodes, clients, or data collectors (like IoT devices). Each client device trains the model locally using its own data and then sends the updated parameters and weights to a central model. This central model then aggregates these updates, learns from them, and shares the new parameters back with the client models.
Here are some terms used in this process:
- Client: Total number of devices involved in the federated learning process.
- Active Client: Some clients are selected to perform training based on certain conditions such as stable network connection, charging status, etc.
- Round: The number of times each active node will perform training locally and then share the final parameters with the central model.
Even when data is made anonymous, personal information can still be revealed. Two cases illustrate this issue:
Case 1: Revealing the Identity of Netflix Users
Netflix shared anonymous viewing data for a competition to enhance its recommendation system. Yet, researchers managed to uncover the identities of individuals by linking this data with publicly available IMDb ratings. By comparing the viewing habits of a small number of users in both datasets, the researchers were able to identify specific people and their viewing preferences. This raised serious concerns about the reliability of anonymization methods.
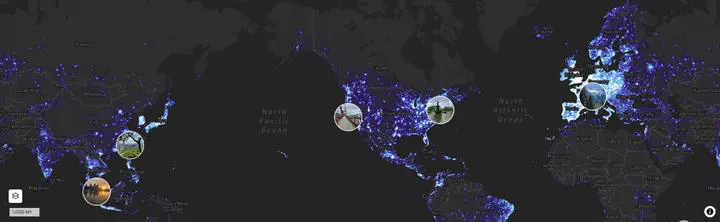
Case 2: Strava Heat Map Exposing Military Locations
Strava, a fitness-tracking app, creates a map showing the activity levels of its users around the world. Although the data is anonymous, it has accidentally revealed sensitive military locations. Researchers discovered that by studying the map, they could figure out how people move in remote areas. In some cases, this helped them locate military bases and track the movements of personnel, disclosing important information.
Measures to Prevent Information Leaks in Federated Learning
To mitigate the risks associated with data de-anonymization, several techniques can be employed:
Stochastic Gradient Descent (SGD): SGD is a technique used in machine learning to improve a model by adjusting weights based on the gradient of the loss function. By adding noise to the gradient calculation, it can enhance privacy protection by making it more difficult to extract exact data points.
Differential Privacy: Differential privacy means sharing information about a group without revealing information about individuals. It ensures that adding or removing a single data point doesn’t significantly change the results, protecting individual privacy.
Federated Averaging: Federated averaging is a method used in federated learning where multiple devices work together to train a model without sharing their raw data. Each device calculates updates to the model based on its local data. Only the updates, not the data itself, are shared and averaged to improve the global model. This approach helps maintain data privacy across decentralized systems.
Conclusion
Protecting personal information in the age of big data is a tough job that requires advanced techniques. The example of Netflix and Strava shows that even when data is anonymized, it can still be at risk of de-anonymization attacks. By using methods like stochastic gradient descent, differential privacy, and federated averaging, organizations can improve their data protection measures and better protect individual privacy.
References
- How To Break Anonymity of the Netflix Prize Dataset Paper
- Anonymity and the Netflix Dataset - An Essay
- Heat Marks the Spot: De-Anonymizing Users’ Geographical Data on the Strava Heatmap - Paper
- Lecture 23 — Differentially Private Machine Learning - By Prof. Gautam Kamath - Lecture Notes
Ukant Jadia
Graduate | ML & Software Engineer
My research interests include applied machine learning, visualization, programming boring stuff.